
Recommender system using fastai in Google Colab
Recommender system using fastai in Google Colab
We will not dive into theory. But if you want to know more, please take a look at this set of videos by Andrew Ng, which explains about recommender systems in a coherent and interesting way. Here we will focus more on practical implementation.
Simply put, you have a set of ratings \(R\), that was given by a set of users \(U\) to a set of movies \(M\). You want to train a model that would be able to predict rating \(R_{ij}\) that a user \(U_{i}\) would give to a movie \(M_{j}\).
To build a recommender system, we need a dataset. We will use this MovieTweetings dataset from Kaggle. It contains ~ 815000 ratings from ~60000 users.
Download data and prepare Google Drive
You can find GitHub link with all the code provided at the end of this article. Also, you can use notebooks directly from google colab. Do not forget to change the runtime type to have GPU as a hardware accelerator.
Download data from here and save it on your Google Drive. Unzip files. (I have created kaggle folder on my Google Drive, you may specify your location)
!unzip /content/drive/My\ Drive/kaggle/MovieTweeting/movietweetings.zip -d /content/drive/My\ Drive/kaggle/MovieTweeting/
Mount your drive to have access to its files
from google.colab import drive
drive.mount('/content/drive')
Data preparation
Import modules that you may need
# For modeling
from fastai.tabular import *
from fastai.collab import *
# For visualization
import seaborn as sns
from matplotlib import pyplot as plt
# For working with data
import pandas as pd
import numpy as np
Specify Path to your data and read it as .csv file. Note that we data is separated by “::”, so take this into consideration. Also, specify columns name, because they`re not been provided in the data.
PATH = Path('/content/drive/My Drive/kaggle/MovieTweeting')
movies = pd.read_csv(Path(PATH, 'movies.dat'), sep='::', names=['id', 'name', 'genre'])
ratings = pd.read_csv(Path(PATH, 'ratings.dat'), sep='::', names=['user_id', 'movie_id', 'rating', 'rating_timestamp'])
users = pd.read_csv(Path(PATH, 'users.dat'), sep='::', names=['user_id', 'twitter_id'])
We have movie id and movie names in different data frames, so we need to merge them. Column “id” in the movie’s dataframe is the same as “movie_id” in the ratings dataframe, so inner merge them. Drop NaN values also.
joined = pd.merge(left=movies.sort_values(by='id'), right=ratings.sort_values(by='movie_id'), left_on='id', right_on='movie_id', how='inner')
joined = joined.dropna(axis=0)
Save your preprocessed dataframe to pickle file
joined.to_pickle(Path(PATH/'movies_preprocessed.pkl'))
Recommender System
Load your data. When training your model you will be able to get some very useful metrics and to decide whether it is working well enough or not. But! Would not be better to test the model on yourself? Pick a user_id that is not presented in the datasets (I choose 99999) and then rate some movies on your choice, then add your user_data to your main dataframe.
data = pd.read_pickle(path/'movies_preprocessed.pkl')
rows = []
user_id = 99999
# movies: Ted, Hachi: A Dog's Tale, The Intouchables, Minions, The Great Gatsby
movie_id = [1637725, 1028532, 1675434, 2293640, 1343092]
ratings = [7, 9, 10, 8, 10]
for i in range(len(movie_id)):
rows.append( dict( {'movie_id' : movie_id[i], 'user_id' : user_id, 'rating' : ratings[i]}))
user_data = pd.DataFrame(rows)
data_reduced = pd.concat([data_reduced, user_data], axis=0)
data_reduced = data[['movie_id', 'user_id', 'rating']]
data_reduced.head()
The resulting dataframe will look something like that:
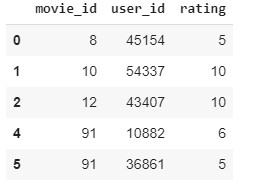 Resulting DataFrame
Resulting DataFrame
Define collab_learner, where n_factors is our embedding vector size, y_range specifies the rating range.
data_collab = CollabDataBunch.from_df(data_reduced, seed=42, valid_pct=0.2, user_name='user_id', item_name='movie_id', rating_name='rating')
learn = collab_learner(data_collab, n_factors=40, y_range=(0, 10), wd=1e-2)
Now you want to learn your model. First of all, find a good learning rate.
learn.lr_find()
learn.recorder.plot()
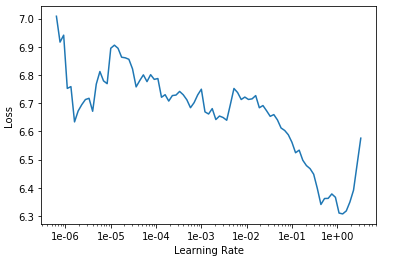
You can play around with the learning rate. I have chosen 1e-3. Trained it for 10 epochs and got ~ 2.55 valid_loss.
learn.fit_one_cycle(10, 1e-3)
Save your model. Don`t forget to move it to your drive!
learn.save("trained_model", return_path=True)
!mv /content/models/trained_model.pth /content/drive/My\ Drive/kaggle/MovieTweeting
Once you have your model trained, you may want to try how does it work. Create test set of unique movies for a specific user. This way we will be able to predict the rating for each movie that could be made by user_id 99999 (by you). Define collab_learner. Do not forget to specify test_data when creating CollabDataBunch.
rows = []
movies = list(data.drop_duplicates(subset='movie_id', keep='first').movie_id)
names = list(data.drop_duplicates(subset='movie_id', keep='first').name)
for i in range(len(movies)):
rows.append( dict({'name': names[i], 'movie_id' : movies[i], 'user_id' : 99999}))
test_data = pd.DataFrame(rows)
# Load your model
data_collab = CollabDataBunch.from_df(data_reduced, test=test_data, seed=42, valid_pct=0.2, user_name='user_id', item_name='movie_id', rating_name='rating')
learn = collab_learner(data_collab, n_factors=40, y_range=(0, 10), wd=1e-2)
learn_loaded = learn.load(Path('/content/drive/My Drive/kaggle/MovieTweeting/trained_model'))
Get predictions.
preds, y = learn_loaded.get_preds(DatasetType.Test)
Show top-10 movies for user_id 99999
for idx, (score, name) in enumerate(sorted(zip(preds, top_names), reverse=True)):
if idx >= 10:
break
print("Score: ", round(float(score), 2), " for movie: ", name)
Here is the output for me:

It seems that the predictions are pretty accurate because I would definitely rate 9ÔÇô10 any of these movies.
Conclusion
We have built a movie recommender system using a real dataset that can make predictions pretty accurately. But all we have done is a jupyter notebook in google colab, it can be used only by us, how can we share our model? What if you want to deploy your ML model? This is a perfect article about end-to-end machine learning.
References
-
Andrew Ng set of videos on recommender systems https://www.youtube.com/watch?v=a-v5_8VGV0A&list=PLjMXczUzEYcHvw5YYSU92WrY8IwhTuq7p&index=8
-
fastai course https://course.fast.ai/
-
MovieTweetings Kaggle dataset https://www.kaggle.com/tunguz/movietweetings
Code available on Github:
Let me know your feedback. If you like it, please recommend and share it. Thank you.

